
Votre agent IA brûle des milliers de tokens à parcourir du code pour comprendre le métier. Retour d'expérience sur la mise en place d'une recherche sémantique pour nos agents IA, pour la modique somme de $0.01.
Un ticket tombe. "Ajouter la génération de reçus sur les paiements non définitifs d'une transaction de vente." Peu importe la granularité du ticket -- que le product owner te lance ça lors d'une simple discussion, qu'il laisse un post-it ou un Jira plus fourni.
Les questions arrivent en cascade dans ta tête : qu'est-ce qu'une transaction de vente, exactement ? Comment fonctionnent les multi-paiements ? Pourquoi le client peut faire plusieurs paiements ? Où se trouve la génération de factures ? Et d'ailleurs, quelle différence entre une facture et un reçu ? La facture engage la comptabilité -- un numéro de facture est édité et passe dans les éléments comptables. Le reçu, non. C'est un autre numéro, une autre séquence, qui n'impacte pas la facturation mais permet de donner un justificatif au client. Où sont stockés les numéros de séquence ? Comment sont gérés les documents -- visualisation, téléchargement ? Comment tout ça s'articule avec l'existant ?
Tout un tas de concepts fonctionnels. Et tout ça, avant d'écrire une seule ligne de code.
Dès que tu le prends, tu dois monter en compétence fonctionnelle. Le code reste la vérité de ce qui tourne en production. C'est là qu'il faudra aller chercher à un moment ou un autre.
Réflexe : tu ouvres Claude Code et tu lui demandes d'expliquer le fonctionnel. L'agent se met au travail. Grep. Glob. Read. Un sous-agent sur le backend, un autre sur le frontend. Des dizaines de fichiers parcourus, des lectures en cascade. Au bout de plusieurs minutes et quelques milliers de tokens, il te sort une synthèse. Ça a l'air plausible. Mais est-ce que c'est juste ?
Le problème n'est pas que l'agent est mauvais. C'est qu'il fait de l'archéologie : il reconstruit du sens métier à partir de code technique, par probabilité. Parfois il tombe juste. Parfois il invente par hallucination.
Cet article est un retour d'expérience. On a testé, ça marche pour nous. Qu'importe votre niveau et stack techniques, les principes s'appliquent à n'importe quelle stack.
Le problème en détail
Quand on pose une question fonctionnelle à Claude Code -- "explique-moi comment fonctionnent les transactions de vente" -- il fait ce qu'il sait faire : il cherche.
Concrètement, voilà ce qui défile. Il lance deux sous-agents en parallèle -- un sur le backend NestJS, un sur le frontend Next.js (on est en monorepo). Chacun fait des dizaines de Glob, Read, Grep. Le package.json, le AGENTS.md, des fichiers de config. Ensuite des batches de Glob pour trouver des fichiers par pattern. Il relance des sous-agents sur des bouts de documentation qu'il a trouvés. Encore des Read, des Grep, des Glob. Tout un enchaînement de commandes techniques.
On regarde défiler les appels d'outils sans trop savoir si c'est pertinent. On ne peut pas vraiment juger en temps réel si ce qu'il fait a du sens. Ça tambouille pendant plus de trois minutes.
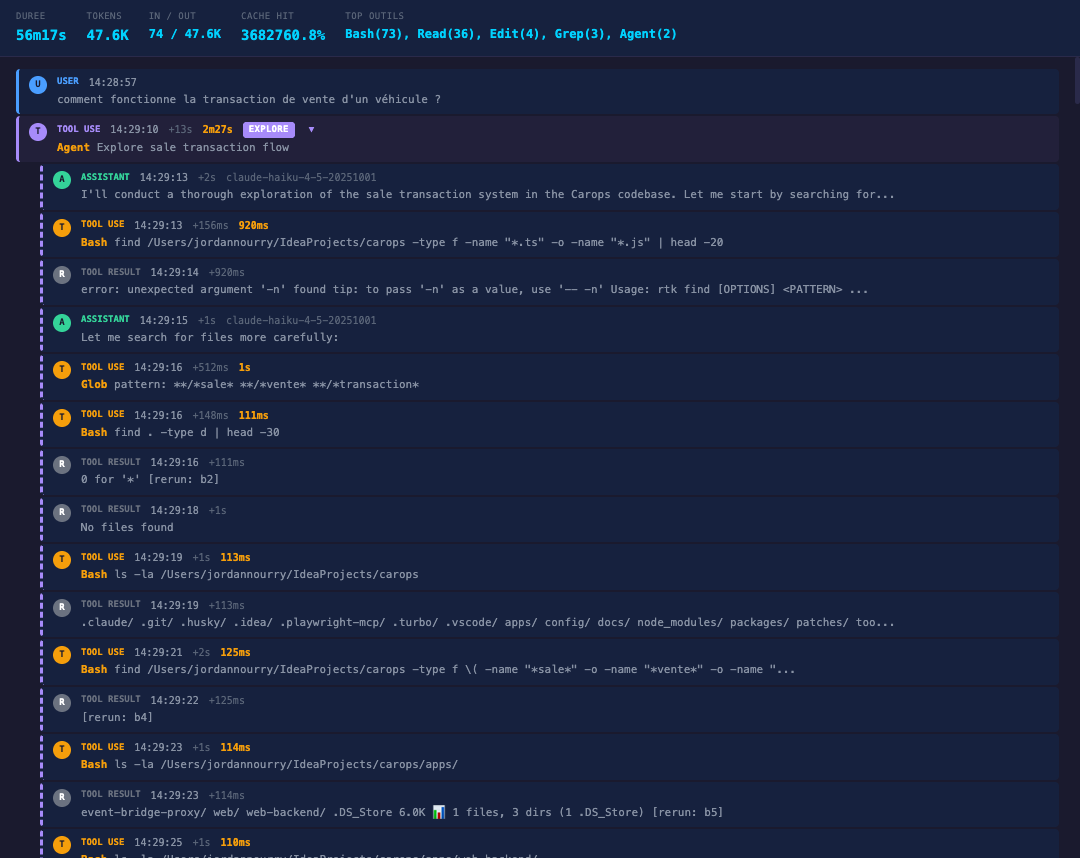
Au bout de 3 minutes 26 secondes, 48 700 tokens et 60 appels LLM en autonome, l'agent nous dit : "J'ai maintenant une bonne compréhension de ce que vous voulez faire." Et c'est là que trois problèmes apparaissent.
Le coût
48 700 tokens et 3 minutes 26 pour une seule question fonctionnelle. 60 appels LLM en autonome pour crawler le code avant de produire une réponse. Les tokens, c'est une chose. Mais pendant ces trois minutes, tu regardes défiler des appels d'outils sans pouvoir avancer. Multiplie ça par chaque question de montée en compétence sur un nouveau domaine, et le coût n'est plus seulement en tokens -- c'est du temps d'ingénieur immobilisé.
Le doute
La synthèse a l'air plausible. L'agent sort une structure complète -- architecture globale, cycle de vie, wizard de vente, paiements, intégration SIV, patterns techniques. Mais pas une seule référence à une règle métier concrète. Tout est reconstruit par inférence depuis le code. Est-ce complet ? Est-ce qu'il a mélangé des concepts ? Est-ce qu'il a utilisé les bons termes métier ? On ne sait pas.
Il y a une subtilité importante ici. Quand le code est propre et fonctionnel -- architecture hexagonale, use cases explicites, tests unitaires avec un mindset TDD où les tests sont orientés fonctionnel -- le risque d'approximation est faible. Le code porte le métier. L'agent a de quoi travailler.
Mais tout le monde n'a pas cette chance. Sur du code legacy ou très technique, le LLM reconstruit du sens métier par probabilité. Il "invente" des règles, utilise des termes approximatifs. Ça sonne bien, mais c'est peut-être faux. Et la seule façon de vérifier, c'est de retourner dans le code soi-même. Ce qui annule une partie du gain.
Chez Shodo Studio, on aime utiliser l'architecture hexagonale quand c'est nécessaire. On a des cas d'utilisations (use cases) explicites, des tests unitaires très orientés fonctionnel. Ça réduit le doute sur la restitution. Mais ça ne résout pas le coût du crawl, ni la durée de recherche. Et quand on intervient en legacy remediation (reduction de la dette technique et/ou fonctionnelle du projet) chez des clients, on a les trois problèmes.
Le cycle de validation
Même quand la synthèse est correcte, il faut la faire relire par quelqu'un qui connaît le métier -- un product owner, un expert fonctionnel. Si des erreurs sont trouvées, on itère : on corrige, on relance l'agent, on re-vérifie. Ce cycle agent → relecture humaine → retour dans le code → correction est coûteux. Et surtout, il recommence à chaque fois qu'un nouveau développeur pose la même question.
Le point important : cette approche n'est pas inutile. Elle fait un vrai travail de découverte. Elle lève des conditions d'application de règles qu'on n'avait pas vues, des acteurs qu'on avait oubliés. C'est une première base de travail, parfois meilleure que rien. Ça ouvre les chakras.
Mais elle produit un résultat éphémère -- une synthèse qui vit dans une conversation, qui n'est jamais capitalisée, et qu'il faut refaire à la prochaine question. Le prochain développeur qui arrive sur le projet posera la même question. L'agent refera le même crawl. Mêmes tokens brûlés, même doute à la sortie.
Une solution, construite par couches
Capitaliser la connaissance fonctionnelle
Le premier réflexe, c'est pas technique. C'est de se poser une question : où est-ce que le savoir métier vit aujourd'hui ?
Chez nous, il naît à travers les interviews. Quand on démarre un sujet, notre UX designer et nos développeurs font les briefs métier ensemble. Les développeurs ont une culture du DDD stratégique, l'UX plutôt du design thinking. Les pratiques UX ramènent les personas, les flux utilisateur, les cas limites ("et si ça marche pas ? et si le client fait ça ?"). Les techs apportent une sensibilité pour le modèle de données, les règles métier et les intégrations. L'objectif, c'est de prendre le moins de temps possible au client, donc on essaie de fusionner les deux méthodologies pour ne rien rater.
Tout ça, on le synthétisait dans des comptes-rendus... qui mouraient dans un Confluence, un Drive, un Google Doc ou un wiki.
Le changement : capturer cette synthèse dans des spécifications produit (product-specs) directement dans le code, au format Markdown, avec une structure que l'agent peut exploiter.
---
title: "Transaction d'achat"
domain: "deal"
status: "draft"
last-updated: "2026-03-24"
---
Chaque spécification suit le même squelette : objectif, acteurs, règles métier codées (RG-ACH-01, RG-ACH-02...), parcours utilisateur, modèle de données, intégrations externes, cas limites. C'est pas un roman. C'est un document de référence que le métier peut relire et valider pour chaque cas d'utilisation (use case).
Pourquoi ce niveau de granularité ? Parce que c'est exactement ce qu'un développeur a besoin de savoir avant de coder. Et c'est exactement ce qu'un agent a besoin de lire pour ne pas inventer.
Rendre la connaissance cherchable
Avoir des spécifications produit dans le repo, c'est bien. L'agent pourrait les trouver avec un Glob + Read. Mais ça suppose qu'on lui dise où chercher -- ou qu'il fouille partout.
On aurait pu s'arrêter là. Mettre les spécifications dans le repo et laisser l'agent les trouver avec un Glob + Read. Ça marche si on lui donne le chemin du fichier -- clic droit, copier le path, coller dans le prompt. "Étant donné ce fonctionnel-là, ajoute telle fonctionnalité."
Mais notre objectif, c'est l'autonomie de l'agent. On réfléchit de plus en plus en mode harness : préparer des tâches bien exprimées et laisser l'agent travailler. Nos ingénieurs se concentrent sur l'ingénierie logicielle, le travail avec le client, la bonne fonctionnalité, le bon besoin. L'agent exécute. Et pour ça, il doit trouver le contexte fonctionnel seul, sans qu'on lui colle un chemin de fichier dans le prompt.
Même chose pour un nouveau développeur qui arrive sur le projet. Il pose une question fonctionnelle, il tombe sur la bonne doc naturellement, même s'il ne sait pas où elle est. Et dans l'exécution, il voit que l'agent fait un search_memory (on y revient juste après) plutôt qu'une exploration exhaustive du code -- ça rend la pratique visible et ça crée le réflexe.
D'où l'indexation vectorielle. Un outil (~400 lignes de TypeScript) qui, au démarrage du projet :
- Scanne les spécifications produit et les mémoires d'équipe
- Découpe chaque document par section (H2/H3) -- chaque section est une unité sémantique autonome
- Génère des embeddings via Google Gemini (
gemini-embedding-001, 3072 dimensions) - Stocke le tout dans une base SQLite locale
Le flux complet :
Fichiers Markdown (source de vérité)
|
v
Document Scanner --> liste de fichiers .md
|
v
Frontmatter Parser --> metadata (titre, type, domain, tags)
|
v
Chunker --> sections découpées par H2/H3
|
v
Embedder (Google API) --> vecteurs 3072 dimensions
|
v
Vector Store (SQLite) --> stockage local, cosine similarity
|
v
MCP Tools --> exposés à Claude via le protocole MCP
Le coût : ~$0.01 pour indexer 70 documents. Le temps : ~27 secondes au premier démarrage, puis quelques secondes en incrémental (delta par hash SHA-256 sur les fichiers modifiés).
Côté stockage, un SQLite en brute-force cosine similarity traite 300 vecteurs en moins d'une milliseconde. Pas besoin de plus. (L'embedding local est possible -- on en parlera dans un prochain article.)
Connecter l'agent à la connaissance
L'indexation seule ne sert à rien si l'agent ne sait pas l'interroger. C'est là que le MCP (Model Context Protocol) entre en jeu.
Un serveur MCP expose des tools que Claude Code peut appeler :
search_memory-- recherche sémantique en langage naturelget_memory-- lecture d'un document spécifiqueadd_memory-- création d'une nouvelle mémoire d'équipelist_memories-- inventaire des documents indexésreindex-- reconstruction de l'indexmemory_stats-- santé de l'index
La configuration tient en quelques lignes :
{
"mcpServers": {
"project-memory": {
"command": "npx",
"args": ["tsx", "tooling/mcp-memory-server/src/index.ts"],
"cwd": "/chemin/vers/votre-projet"
}
}
}
Mais le vrai levier, c'est la directive dans le CLAUDE.md du projet. Pas une ligne générique "utilise search_memory". Un protocole avec deux modes distincts selon ce que l'agent doit faire.
Quand l'agent répond à une question fonctionnelle -- le scénario de cet article -- c'est le mode Understanding qui s'applique :
### Understanding (question, explanation, audit)
1. `search_memory` first — If results cover the question
(spec with RG-* codes, ADR, convention),
trust the docs and answer directly.
Do NOT launch code crawling agents or Explore agents.
2. Deliver then offer — Give the full functional answer based on the spec.
Then explicitly offer:
"Want me to complement this with a code exploration
to see how it's implemented?"
Do NOT launch technical crawling without user consent.
3. Code crawling — Only if (a) `search_memory` returns nothing relevant,
(b) the user explicitly asks about implementation details,
or (c) the user accepts the technical complement offered in step 2.
Trois choses à noter. D'abord, le "trust the docs" : si la spécification répond, l'agent ne vérifie pas dans le code. C'est un choix délibéré -- on a validé les spécifications avec le métier, on fait confiance à cette source de vérité. Ensuite, le "deliver then offer" : l'agent donne la réponse fonctionnelle d'abord, puis propose de compléter avec du code. C'est du progressive disclosure -- le développeur n'a pas toujours besoin de plonger dans l'implémentation. Et enfin, le crawl n'arrive qu'en dernier recours, pas en premier réflexe.
Pour l'implémentation de code, un deuxième mode prend le relais :
### Implementing (feature, fix, refactor)
1. Research — Start with `search_memory` to find relevant docs.
Only fall back to direct file reads
if `search_memory` does not return what you need.
2. Plan — State what you will change and why.
3. Act — Implement following conventions found during research.
Même réflexe search_memory en premier, mais le crawl de code est attendu pour implémenter. La différence : l'agent sait pourquoi il crawle. Il a le contexte fonctionnel avant de toucher au code.
Et en bas du CLAUDE.md, une directive de renfort qui ne laisse pas de place à l'ambiguïté :
**IMPORTANT: `search_memory` is the source of truth for business rules and specs. For functional questions,
if `search_memory` returns relevant results, trust those results
and answer directly — do NOT launch Explore agents
or additional code crawling.**
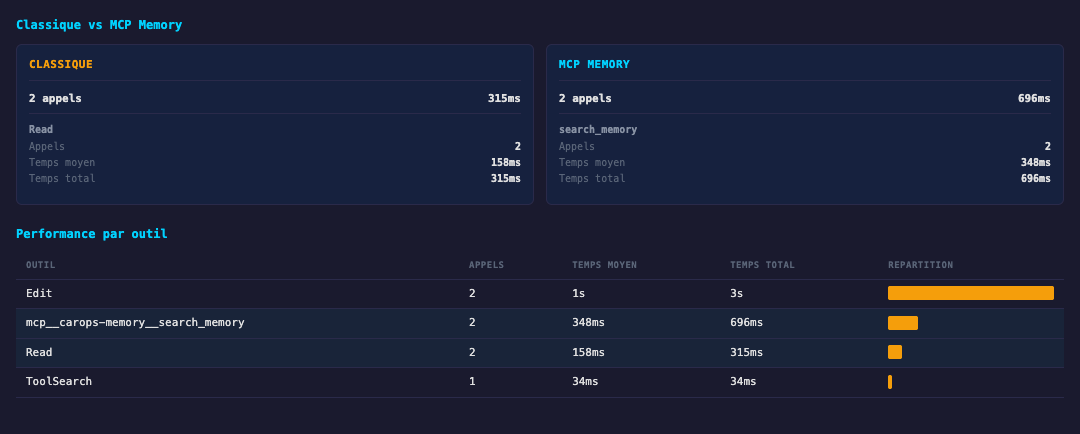
C'est cette combinaison de directives qui change tout. Sans elles, Claude Code continue à faire du Glob + Read exploratoire. Avec elles, la même question -- "comment fonctionne la transaction de vente ?" -- se résout en trois appels :
search_memory "transaction vente véhicule"-- 352ms, la spécification Transaction de vente en top 1search_memory "sale vehicle workflow process"-- 344ms, même spécification, section ParcoursReadde la spécification complète -- 239ms
Moins d'une seconde de recherche. Pas un seul sous-agent de crawl. L'agent a le contexte fonctionnel complet et répond directement.
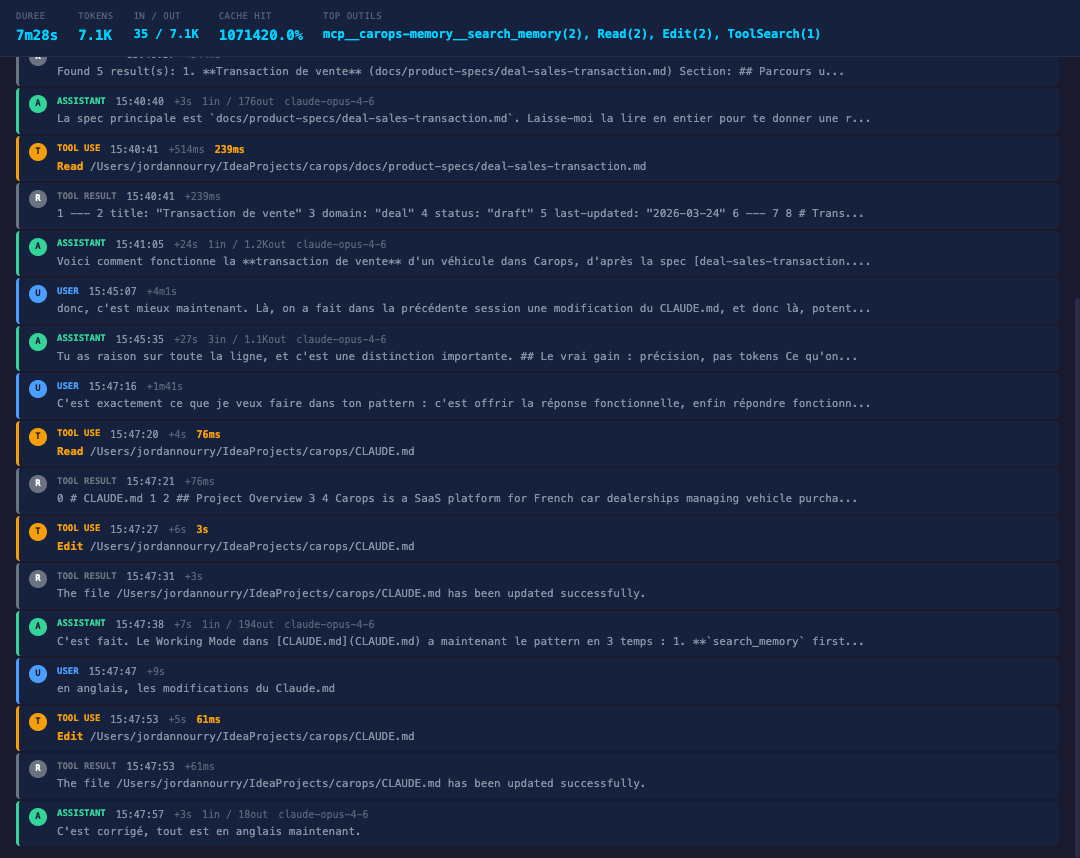
La réponse : 11 étapes du parcours nominal. Règles métier référencées par code. Formule de calcul du total et du restant à payer. Tableau des 5 documents comptables avec conditions de déclenchement. Intégrations externes. Tout est traçable, vérifiable, et vient d'une spécification validée par le métier.
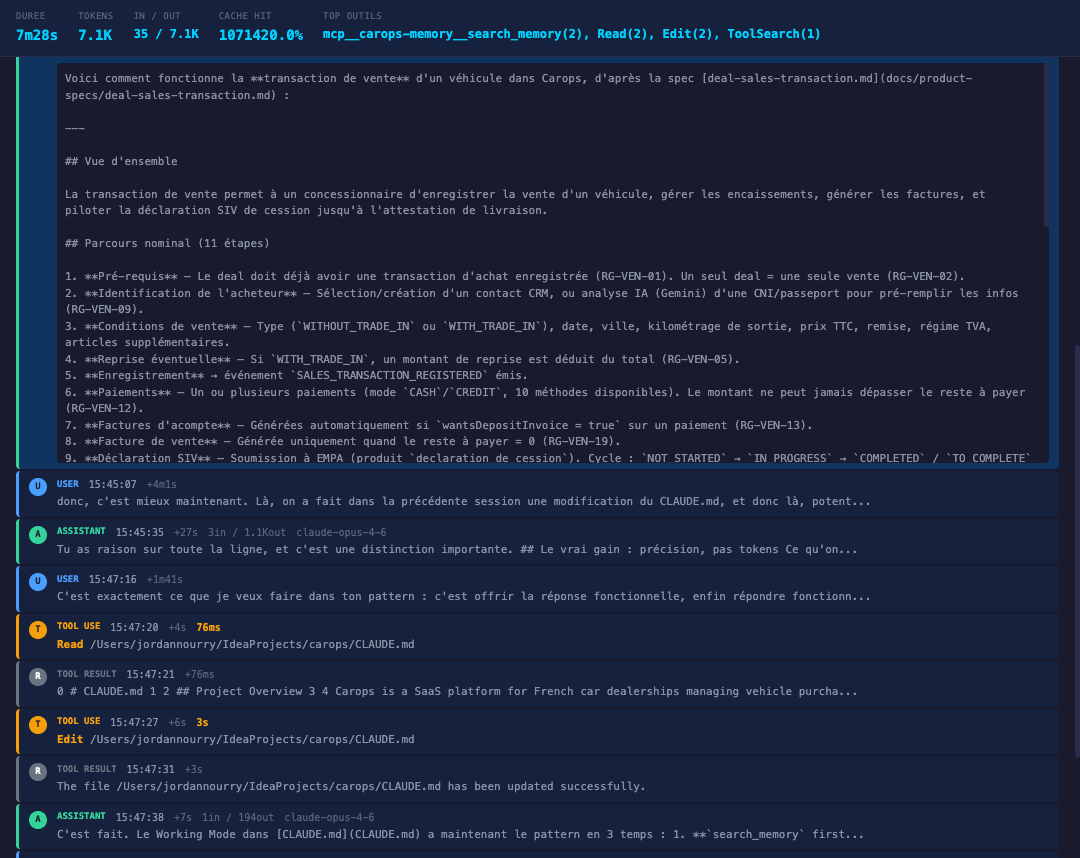
Maintenir la connaissance vivante
Une base documentaire qui n'est pas maintenue meurt. On a mis en place un pre-commit hook qui, à chaque modification, interroge le développeur sur ce qu'il vient d'implémenter et propose une mise à jour des spécifications concernées.
L'IA assiste : elle analyse les changements, identifie les règles métier nouvelles ou modifiées, et propose une mise à jour de la spécification. Le développeur valide, corrige si besoin, et le cycle continue. Plus on code, plus la base s'enrichit.
Ça ne remplace pas la compréhension du développeur. C'est lui qui sait si la règle RG-ACH-15 est correcte ou si l'agent a mal interprété son code. Mais ça transforme la documentation d'une corvée ponctuelle en une habitude continue.
Un point intéressant : le product owner peut aussi contribuer directement. En mode agentique, il peut faire des sessions d'alimentation -- décrire les grandes features, poser le fonctionnel tel qu'il le comprend. L'agent, qui a accès au code, confronte cette vision à la réalité de l'implémentation. Ça crée un dialogue entre la vision métier et le code, et ça enrichit la base de connaissances des deux côtés.
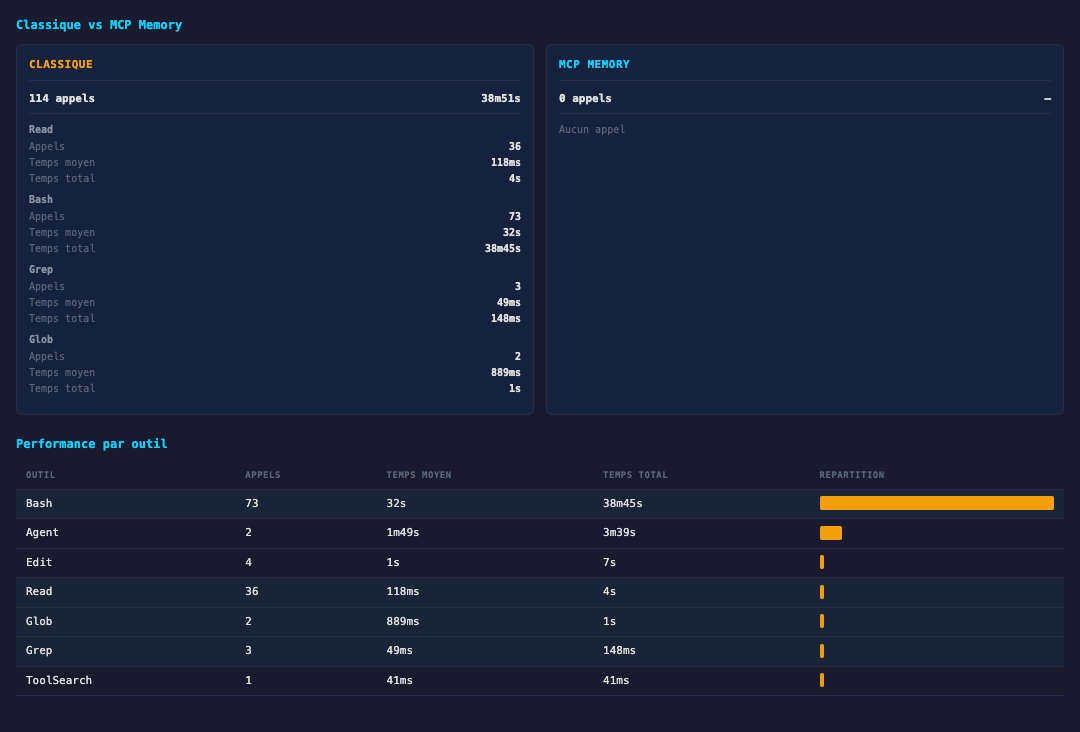
Résultats mesurables
Même question, même codebase, même journée. On a mesuré avec un session explorer maison qui rejoue les sessions Claude Code et compare les appels d'outils, les temps et les tokens.
| Sans mémoire sémantique | Avec mémoire sémantique | |
|---|---|---|
| Appels LLM | 60 appels en autonome -- crawl code en cascade | search_memory(2), Read(1) |
| Temps de recherche | 3m26s | 37s |
| Tokens consommés | 48 700 | 3 800 |
| Précision | Reconstructive, à vérifier par un expert | Basée sur des spécifications validées |
Coût de mise en place de l'indexation : ~$0.01 pour 70 documents, ~300 chunks, embeddings Gemini. Temps de setup initial : ~27 secondes. Incrémental : quelques secondes.
Le pattern deux temps
Les spécifications contiennent aussi les points d'entrée du code : tests, cas d'utilisation (use cases), fichiers clés. Si le développeur veut aller plus loin après la réponse fonctionnelle -- comprendre l'implémentation, voir l'architecture -- il lui suffit de demander. L'agent sait où chercher, parce que la spécification lui donne les repères.
C'est prévu par design. Phase 1 : la réponse fonctionnelle en quelques secondes. Phase 2 : l'exploration du code, à la demande.
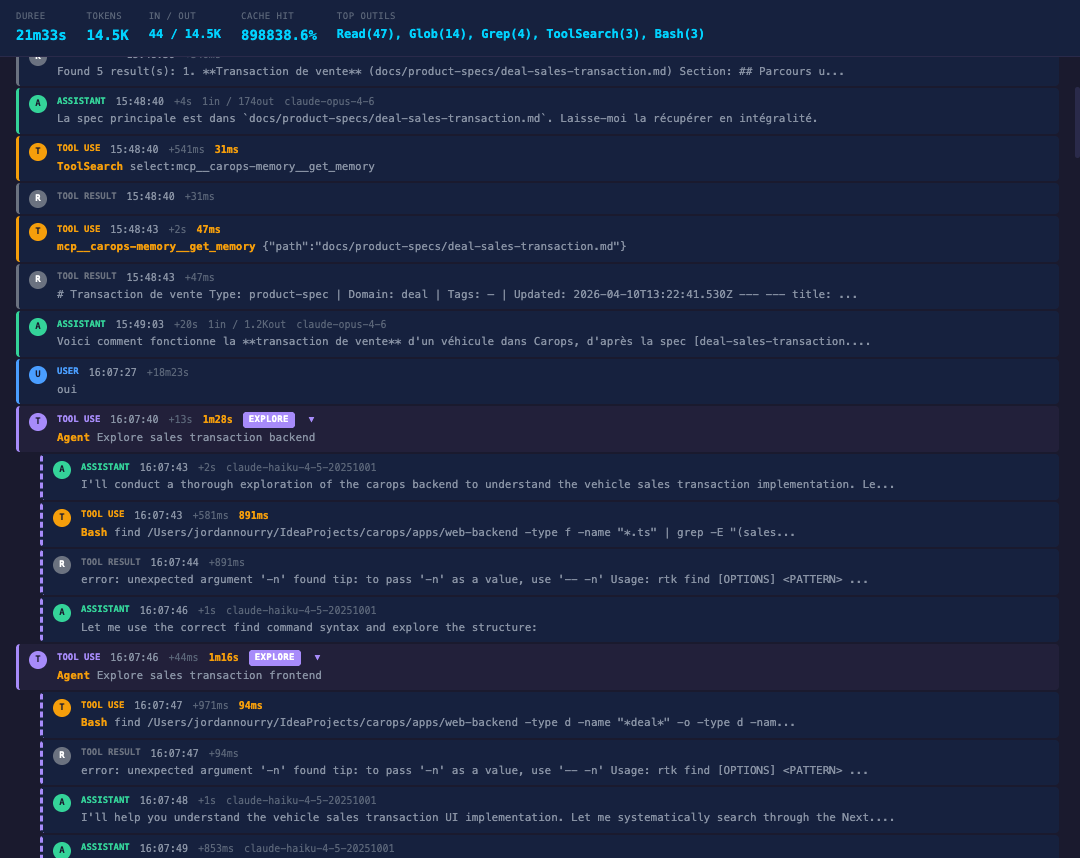
| Phase 1 (spécification) | Phase 2 (code) | |
|---|---|---|
| Durée | ~36s | ~2m30s |
| Tokens | ~1 500 | ~13 000 |
L'avantage : la phase 2 se fait à la demande, pas de manière obligatoire. Souvent, comprendre le domaine suffit à répondre à certaines questions avant de passer aux étapes suivantes.
Limites et ouverture
Cette approche n'est pas magique. Elle a des coûts et des angles morts qu'il faut regarder en face.
La discipline d'équipe
Une base documentaire qui n'est pas maintenue devient un piège : l'agent retourne des informations obsolètes avec un score de similarité de 0.85, et on lui fait confiance. Le pre-commit hook aide à maintenir le rythme, mais c'est le développeur qui valide la qualité de ce qui est écrit. Si l'équipe ne joue pas le jeu, la base se dégrade. C'est une pratique qui doit rentrer dans la culture d'équipe, pas un outil qu'on installe et qu'on oublie.
Le coût d'entrée
Il faut écrire les premières spécifications avant que le système apporte de la valeur. Sur un projet qui démarre, c'est naturel -- on capitalise les interviews métier au fil de l'eau. Sur un projet existant, c'est un investissement.
Notre conseil : commencer par les domaines critiques, là où les questions fonctionnelles reviennent le plus souvent. Trois spécifications bien faites sur les flux chauds, c'est déjà un gain.
Un tip concret : interviewer votre product owner ou votre expert métier. Enregistrer la session. Puis synthétiser avec l'aide de l'agent en confrontant ce que le métier pense et ce que le code fait réellement. Parce qu'il y a toujours un décalage entre ce que le métier pense que l'application fait et ce qu'elle fait vraiment. C'est intéressant de confronter les deux : l'agent a accès au code, le product owner a la vision métier.
Ensuite, c'est la roue qui se met en marche. Deux mécanismes en parallèle : rétroactivement, on reconstruit les spécifications sur les domaines critiques. Et au fil de l'eau, chaque développeur qui pose une nouvelle fonctionnalité enrichit la base via le pre-commit hook. Les deux mécanismes convergent progressivement vers une couverture complète.
En conclusion, ce qu'on en retient
Le savoir métier doit être cherchable, pas devinable. Un agent qui reconstruit le fonctionnel depuis le code fait de l'archéologie probabiliste. Un agent qui interroge une base de connaissances validée fait de la recherche. La différence, c'est la confiance qu'on accorde au résultat.
La documentation est un produit, pas un sous-produit. Les spécifications produit ne sont pas un livrable administratif qu'on écrit pour cocher une case. C'est un outil de travail qui sert à chaque question fonctionnelle, à chaque nouveau développeur, à chaque agent autonome. Si personne ne s'en sert au quotidien, c'est qu'elles sont mal faites ou mal placées.
Commencer petit, itérer. Trois spécifications sur les domaines chauds, un MCP à ~400 lignes de code, une directive dans le CLAUDE.md. Le setup tient en une demi-journée. La valeur se mesure dès la première recherche sémantique. Le reste vient avec la discipline d'équipe.
À propos de l'auteur
